
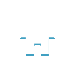
不可达基数k就是对任意小于k的基数,取幂集的基数仍然小于k并且由任意小于k个小于k的集组之并的基数仍然小于k。而对比弱不可达基数只要满足<k的任意基数的后继仍然<k就行。而具有以上相同性质的可数基数就是阿列夫零。
马洛基数:又称马赫罗基数,对于所有K,正则基数 β 的初始段(即 β 以下的所有基数)中都包含一个K基数。这里的K在这个基数以上所有的正则无限基数的并集中,删去所有小于K的基数后,剩余的基数集合是一个K的闭集。也就是一个马洛基数κ之下的不可达基数组成驻集,小于κ的所有正则基数集合是κ的驻子集,则κ为马洛基数,说明白点就是任意不可达基数k,其他不可达基数在这个k前面形成无界闭集取驻集族为{a {0,1} 都存在一个κ个元素的子集使f在这个集上的值相同。也是,最小不可达基数κ,需要满足cfκ=κ,a<κ→2^a<κ的基数,一个2-不可达基数κ是第κ个不可达基数,一个超不可达基数就是κ-不可达基数,每一个马洛基数κ之下的不可达基数组成驻集,小于κ的所有正则基数集合是κ的驻子集,则κ为马洛基数,说明白点就是任意不可达基数k,其他不可达基数在这个k前面形成无界闭集,则此k为马洛基数,第马洛基数个不可达基数一定是马洛基数。然后是2-马洛基数,下面的马洛基数形成驻集,超马洛基数,κ是κ-马洛基数。
不可描述基数:基数K称为∏n不可描述基数如果对于每个∏m命题(φ,并且设置A?∨κ与(Vκ+n,∈,A)╞φ存在一个α<κ与(V α+n,∈,A ∩Vα)╞φ。这里看一下具有m-1个量词交替的公式,最外层的量词是通用的。∏n不可描述基数以类似的方式定义。这个想法是,即使具有额外的一元谓词符号(对于A)的优势,也无法通过具有m-1次量词交替的n+1 阶逻辑的任何公式将κ与较小的基数区分开来(从下面看)。这意味着它很大,因为这意味着必须有许多具有相似属性的较小基数。如果基数κ是∏nm,则称它是完全不可描述的——对于所有正整数m和n都难以描述。也是,这里不可描述基数是指一类大基数,指用∏nm或者是∑nm公式的概念和模型论工具所定义的基数,若对任何仅含一个二阶自由变元X的∏nm公式或∑nm公式Φ(X),当有α层结构〈Vα,∈?Vα,R〉满足Φ(R)时,即〈Vα,∈?Vα,R〉?Φ(R)成立时,存在β<α,使β层子结构也满足Φ(R),即〈Vβ,∈?Vβ,R∩Vβ〉?Φ(R∩Vβ),则称基数α为∏mn或∑mn不可描述基数,注意到反射原理是指全域中的任何一阶公式可以用某一层Vβ中的相对化公式来代替,此处的不可描述性,就是指,在α层结构中真的公式,必可在α之前的某β层中为真,公式加以适当的限制,这种不可描述基数必然是很大的一类大基数,κ是强不可达基数,当且仅当κ是∏10不可描述基数,又当且仅当κ是∑11不可描述基数,κ是弱紧基数,当且仅当κ是∏11不可描述基数,若κ是可测基数,则κ是∏21不可描述基数。
可迭代基数:将基数κ定义为可迭代的,前提是κ的每个子集都包含在弱κ-模型M中,其中在κ上存在一个M-超滤器,允许通过任意长度的超幂进行有根据的迭代。Gitman给出了一个更好的概念,其中一个基数κ被定义为α-iterable 如果仅需要长度为α的超幂迭代才能有充分根
拉姆齐基数:让[ κ ]<ω表示κ的所有有限子集的集合。如果 对于每个函数, 基数 κ称为 Ramsey
f : [ κ ]<ω→{0,1}
存在基数为κ的集合A对于f是齐次的。也就是说,对于每个n,函数f在A的基数n的子集上是常数。如果A可以被选为κ的固定子集,则基数κ被称为不可言说的Ramsey。如果对于每个函数, 基数κ实际上被称为Ramsey
f : [ κ ]<ω→{0,1}
存在C,它是κ的一个闭无界子集,因此对于C中具有不可数共尾性的每个λ,都存在一个与 f 齐次的入的无界子集;稍微弱一点的是lamost Ramsey的概念,其中对于每个λ<κ,需要有序类型λ的f的同质集。
将基数κ定义为可迭代的,前提是κ的每个子集都包含在弱κ-模型M中,其中在κ上存在一个M-超滤器,允许通过任意长度的超幂进行有根据的迭代。
Gitman给出了一个更好的概念,其中一个基数κ被定义为α-iterable 如果仅需要长度为α的超幂迭代才能有充分根据。
也就是,拉姆齐基数定理确立了ω具有 R基数推广到不可数情况的特定性质,令让[ κ ] <ω表示κ的所有有限子集的集合,一个不可数的基数 κ 称为 R 如果,对于每个函数f : [ κ ] <ω → {0, 1},有一个基数κ的集合A对于f是齐次的,也就是说,对于每个n,函数f在来自A的基数n的子集上是常数,如果A可以选择为 κ 的平稳子集,则基数κ被称为不可称的R,如果对于每个函数, 基数κ实际上称为Rf : [ κ ] <ω → {0, 1},有C是κ的一个封闭且无界的子集,因此对于 C 中的每个λ具有不可数的共尾性,有一个λ的无界子集对于f是同质的;稍微弱一点的是几乎 R的概念,其中对于每个λ < κ , f的齐次集都需要阶类型λ,这些 R基数中的任何一个的存在都足以证明0 #的存在,或者实际上每个秩小于κ的集合都有一个尖,每个可测基数都是R大基数,每个 R大基数都是R大基数,介于 R和可测性之间的强度中间属性是κ上存在κ完全正态非主理想 I使得对于每个A ? I和对于每个函数,f : [ κ ] <ω → {0, 1},有一个集合B ? A不在I中,对于f是齐次的,R基数的存在意味着0 #的存在,这反过来又意味着Kurt的可构公理的错误。
强拉姆齐基数:一个为κ的强拉姆齐基数,而且仅当对于每一个A?κ位于一个存在κ上的弱自可的κ-模型M,κ-模型M可数完备,〈M,U〉满足κ-完备,它必然是正确的,因为M在长度小于κ的序列下是封闭的。强拉姆齐基数的力迫相关性质与之前的拉姆齐基数相同,强拉姆齐基数的一致性强于拉姆齐基数。
弱紧致基数:(位于马洛基数后)
k是弱紧致基数是指不可数且满足k → (k )。
所谓k是弱紧致基数,是指在不可数且Lκ,κ-句的集合中至多只使用了k个非逻辑符号的情况下,如果k-能够满足则能够满足。(弱紧致性)记载了两个弱紧致基数的定义。
前者是组合论的性质,后者是模型理论的性质。
首先需要确认这个定义是相同值,还是真的定义了相同的基数,但是以后再进行,这个弱紧致基数具有什么性质,是组合论和模型理论这两个理论。
也是大基数的一种,特殊的强不可达基数,一个基数κ被称为弱紧的,如果κ是强不可达的并且满足树性质或划分性质,从定义可见,弱紧性弱于可测性但强于不可达性,弱紧致基数是大基数理论中的一个核心概念,若语言Lκκ中任何只用到≤κ个非逻辑符号的语句集A有模型,当且仅当A的每个基数κ的子语句集有模型,则称基数κω是弱紧基数,弱紧基数是由匈牙学者爱尔特希和波兰学者塔尔斯基于1961年开始进行研究的,弱紧基数的等价性质很多,例如以无穷组合论中的一些性质来刻画,对于κω,κ是弱紧基数与以下各条等价:
1.κ具有分划性κ→(κ)22。
2.对任何基数γκ及nω,κ具有分划性质κ→(κ)nγ。
3.κ是强不可达基数且有数性质,κ是弱紧基数还与下列这些性质等价。
4.κ是超滤性质。
5.κ有弱超滤性质且κ是强不可达基数。
6.κ有Vκ可扩张性质。
7.κ有序性质。
8.κ是π11不可描述基数。
汉弗(Hanf,W.P.)于1964年与库仑(Kunen,K.)于1977年的工作结合起来,得到如下结论:
弱紧致基数κ是强马赫罗基数,并且κ以下的强马赫罗基数的集合是κ的驻子集.通常的一阶逻辑语言是Lωω,其紧致性定理是:
Lωω的任一语句集A有模型,当且仅当A的每个有穷子集有模型,亦即,语言Lωω是(ω,ω)紧的,上述弱紧基数的定义与此略有不同,如果完全依照ω的这一紧致性而加以推广,则可定义另一种弱紧基数,人们称之为弱紧2基数,基数κω称为弱紧2基数,是指语言Lκκ是(κ,κ)紧的,即对于Lκκ的任何基数≤κ的语句集A,A有模型,当且仅当A的每个基数κ的子语句集有模型,若将先前定义的弱紧基数称为弱紧1基数,则可以证明:
κ是弱紧1基数,当且仅当κ是弱紧2基数,且是强不可达基数,在广义连续统假设之下,弱紧1与弱紧2基数是相同的,弱紧2基数必为弱马赫罗基数
可测基数:(在拉姆齐基数后)
为了定义这个概念,人们在基数κ上或更一般地在任何集合上引入了一个二值度量。对于基数κ,它可以描述为将其所有子集细分为大集和小集,使得κ本身很大,?并且所有单例{ α },α ∈ κ很小,小集的补集很大,并且反之亦然。小于的交集κ大集又大了。
事实证明,具有二值测度的不可数基数是无法从ZFC证明其存在的大基数。形式上,可测基数是不可数基数κ,使得在κ的幂集上存在κ加性、非平凡、0-1值测度。
(这里术语k-additive意味着,对于任何序列A α,α<λ的基数λ<κ,A α是成对相交的小于κ的序数集,A α的并集的度量等于个人A α的措施。)将满足集合a上的下一个的滤波器f称为超滤波器,对于所有的xa,X∈F或A X∈F ω上存在ω-完备非一元超滤波器,当k为不可数基数,k上存在K-完备非一元超滤波器时,k称为可数基数
定理( ZFC )
可测基数为不可达基数,可预测基数公理( Meas ) :“存在可预测基数.”可测基数与初等嵌入,当k是可测基数时,根据k上K-完备非一元超滤波器对v的超幂,构造了一类可拓m和一类函数j:V→M,并给出了 《φ(x1,...,xn):L∈-理论式》
?x1,...,xn∈V(φV(x1,...,xn)?φM(j(x1),...,j(xn)))
对于所有α<K,j(α) =α且j(K ) > k 将j称为从v到m的初等嵌入,k是j的临界点
使用这个初等嵌入,可以显示出可预测基数k的很多性质在这种初等嵌入的存在下,k的可测性具有特征。
也是,可测基数是一个不可数的κ ,因此在κ的幂集上存在加性、非平凡、0-1值测度,而κ-additive意味着,对于任何序列Aα, α<λ 的基数λ<κ,Aα是<κ的序数的成对不相交集, Aα的并集的度量等于个体Aα的测量值。
κ是可测的意味着它是将宇宙V的非平凡基本嵌入到传递类M的临界,并使用了模型理论中的超强构造,由于V是一个适当的类别,因此需要解决一个在考虑超能力时通常不存在的技术问题,当且仅当 κ 是具有κ完全非主超滤器的不可数基数时, κ是可测量的基数,这也意味着超滤器中任何严格小于κ的集合的交集也在超滤器中。
强可展开基数:(位于不可描述基数后)
基数κ是λ不可展开的,当且仅当对于ZFC的基数κ的每个传递模型M负幂集使得κ在M中并且M包含其所有长度小于κ的序列,有非-将M的非平凡基本元素j嵌入到传递模型中,其中j的临界点为κ,且j (κ) ≥ λ,一个基数是可展开的当且仅当它对于所有的序数λ 都是 λ-不可折叠的,一个基数κ 是强 λ 不可折叠的当且仅当对于每个ZFC负幂集的基数 κ 的传递模型 M使得 κ 在M中并且M包含其所有长度小于 κ 的序列,存在一个非-将M的平凡基本嵌入j到传递模型“N”中,其中 j 的临界点为κ,j (κ) ≥ λ,并且 V(λ) 是N的子集,不失一般性,我们也可以要求N包含其所有长度为 λ 的序列,一个基数是强可展开的当且仅当它对于所有 λ 都是强 λ-不可展开的。
强基数:如果λ是任何序数,κ是λ-strong意味着κ是基数并且存在从宇宙V到具有临界点κ和Vλ?M也就是说,M在初始段上与V一致。那么κ是强的意味着它对所有序数λ都是λ-强的。